
이번엔 파이썬 크롤러 라이브러리를 사용하여 학교 공지 사항 크롤링을 진행 해보려고 한다.
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object, or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str() function returns a str
www.crummy.com
뷰티풀스프를 사용하여 html 요소들을 수프 객체로 만들어서 추출 하여 주는 라이브러리를 사용 했다.
import requests
from bs4 import BeautifulSoup
url = 'https://www.naver.com/'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
print(soup)
else :
print(response.status_code)
한마디로 f12를 눌렀을 때 나오는 html 요소들을 쉽게 가져올 수 있도록 뷰티풀 스프를 사용 한 것이다.
그렇다면 목표인 인제대학교 학사 공지를 살펴보자.
일반 | 인제대학교
www.inje.ac.kr
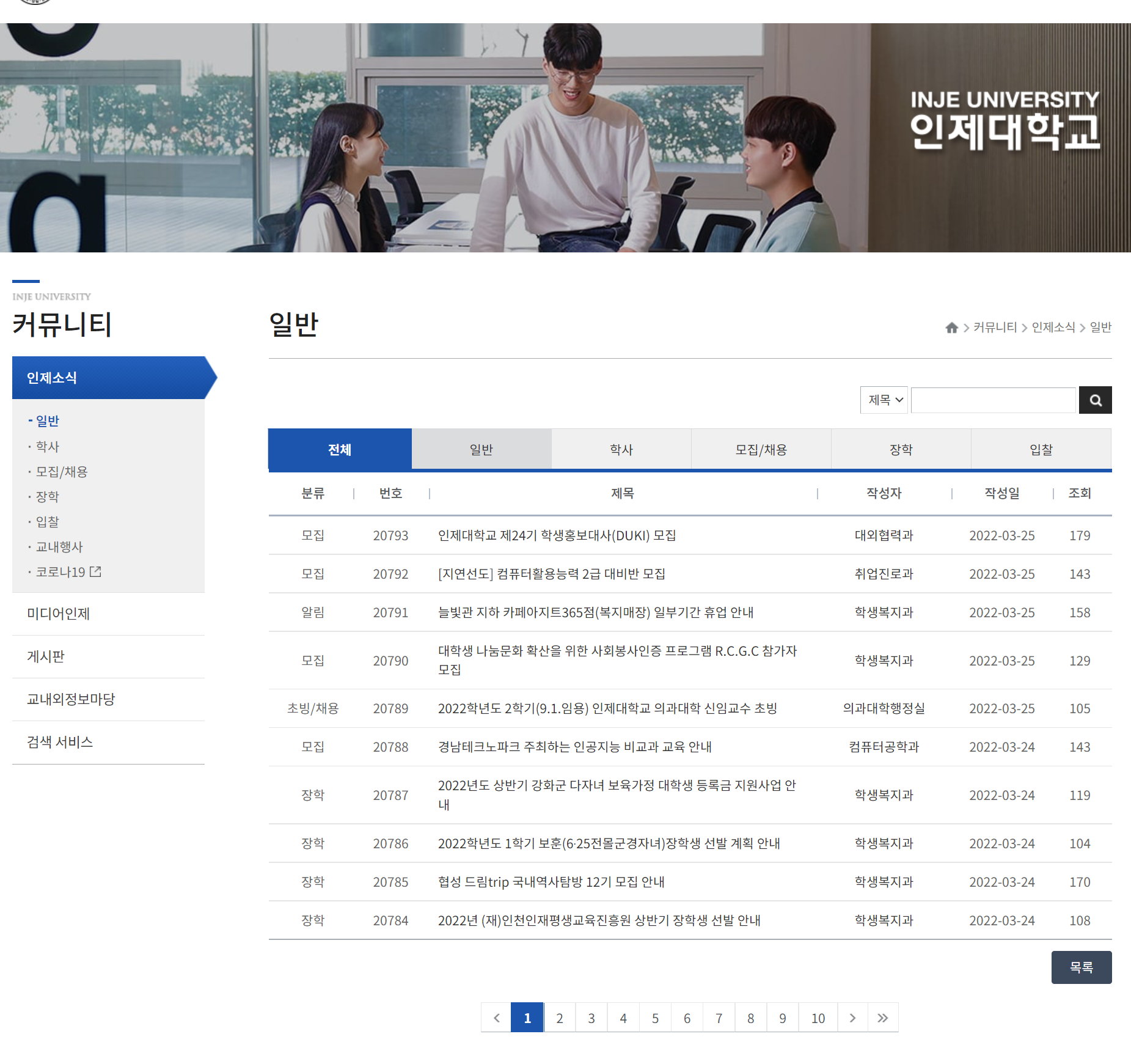
테이블로 만들어진 사이트를 f12로 요소 탐색을 시작했다.
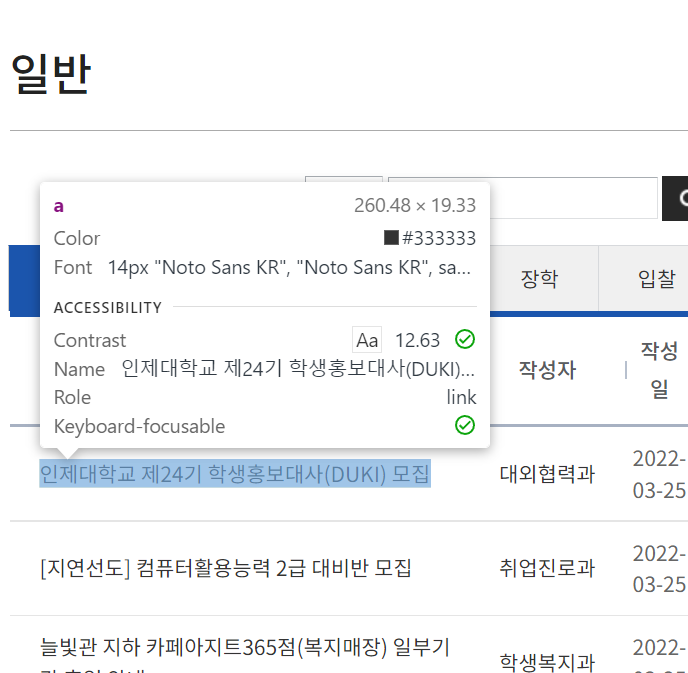
다음과 같이 a태그 안에 어떤 폰트에 위치까지 나오게 된다.
import discord
from discord.ext import commands
import requests
from bs4 import BeautifulSoup #뷰티풀스프와 리퀘스트 임포트 해오기
app = commands.Bot(command_prefix='/') #명령어는 /로 시작
@app.event
async def on_ready():
print('Done')
await app.change_presence(status=discord.Status.online, activity=None)
@app.command()
async def 인제대(ctx): #명령어 이름은 인제대
try:
인제대학교response = requests.get("https://www.inje.ac.kr/kor/Template/Bsub_page.asp?Ltype=5&Ltype2=0&Ltype3=0&Tname=S_News&Ldir=board/S_News&SearchText=&SearchKey=&d1n=5&d2n=1&d3n=1&d4n=0&Lpage=Tboard_L")
#인제대학교response라는 이름으로 사이트 get 해오기
인제대학교response.encoding = 'utf-8'
인제대학교html = 인제대학교response.text
인제대학교soup = BeautifulSoup(인제대학교html, 'html.parser')
#모듈을 가지고 오고 requests 모듈을 사용하여 해당 URL에서 HTML 소스를 가지고 옴. 가지고 온 소스의 인코딩 변환을 해주고, BeautifulSoup 모듈로 데이터를 파싱함.
인제대학교정보 = 인제대학교soup.select('tr') #인제대학교 정보라는 이름으로 tr요소들을 전부
for 정보 in 인제대학교정보[1:10]:
분류, 번호, 제목, 작성자, 작성일, 조회 = 정보.select('td')
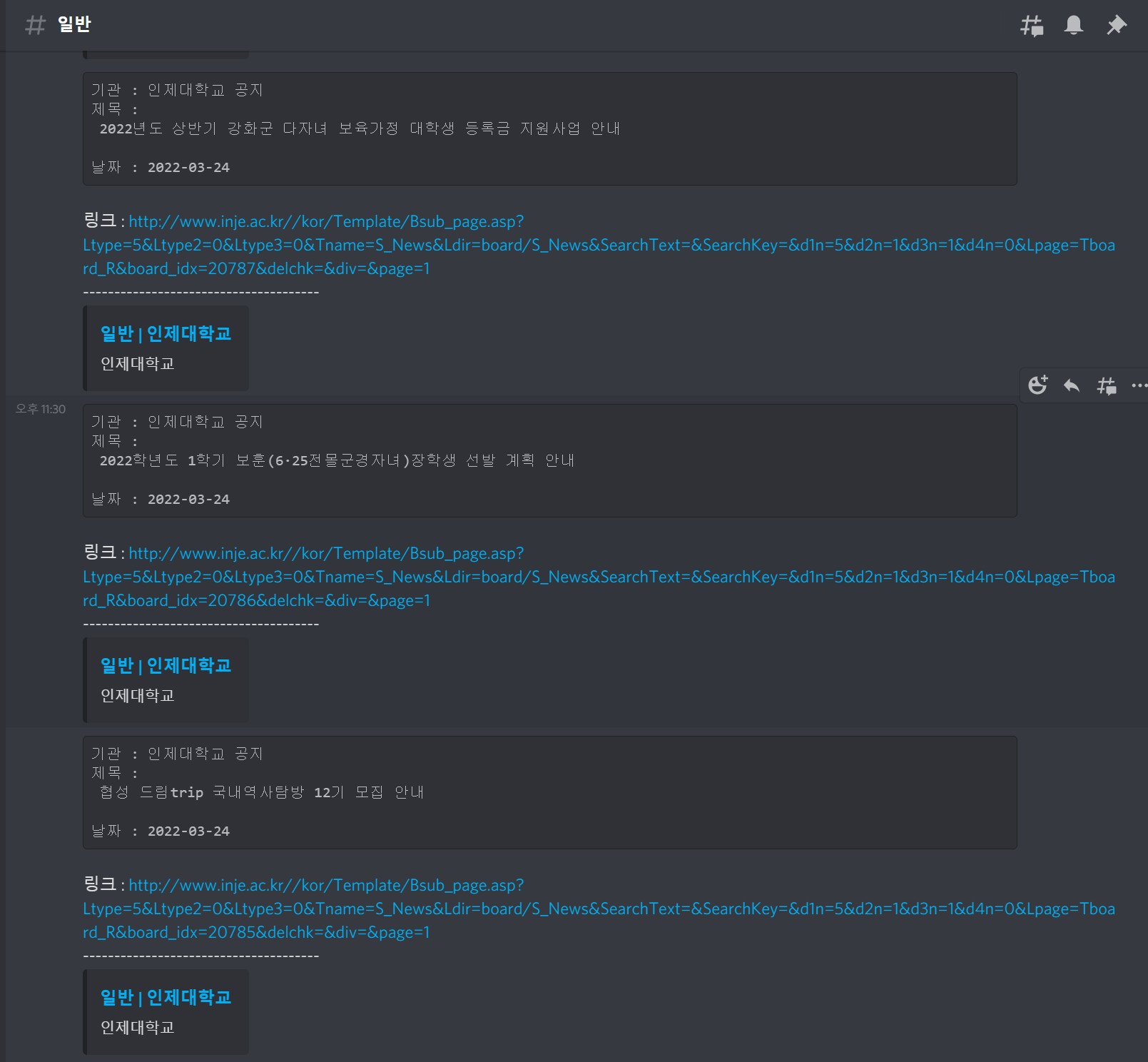
await ctx.send(f'```기관 : 인제대학교 공지\n제목 : {제목.text}\n날짜 : {작성일.text}```\n링크 : http://www.inje.ac.kr/{제목.a["href"]}\n--------------------------------------')
except:
await ctx.send(f'{today.month}월 {today.day}일 {today.hour}시 {today.minute}분 인제대학교 오류 발생')
app.run('OTU3MTU2Njc4ODA0MDU0MDM3.Yj6rnw.A96_6389ZoCpxqhGwY3vebzoDcg')코드에도 설명을 해 두었지만 뷰티풀스프와 리퀘스트 모듈을 임포트해와서 해당 URL에서 HTML소스들을 가져와줍니다. 가져온 소스의 인코딩 변환을 통해 데이터를 파싱하는 과정을 거친다.
모든 app.command는 비동기 방식을 사용한다 따라서 인제대라는 이름을 정의 해주기 전 async 문을 통해 await으로 받아 낼 함수를 지정 해 준다.
for 정보 in 인제대학교정보[1:10]:
분류, 번호, 제목, 작성자, 작성일, 조회 = 정보.select('td')
await ctx.send(f'```기관 : 인제대학교 공지\n제목 : {제목.text}\n날짜 : {작성일.text}```\n링크 : http://www.inje.ac.kr/{제목.a["href"]}\n--------------------------------------')for문을 통해 0번 데이터를 제외한 1~9까지 데이터들을 받아온다. 분류, 번호, 제목, 작성자, 작성일, 조회라는 이름으로 td들을 select 해오면 된다. 그리고 ctx.send를 통해 출력 해준다.
다음 코드는 다음과 같은 실행 화면을 보여준다.
'파이썬 개발 > 디스코드 봇 개발' 카테고리의 다른 글
| [Discord.py] 1. 디스코드 봇 개발의 기초 (5) | 2022.03.26 |
|---|